大数据平台搭建2024(一)
一:基础配置
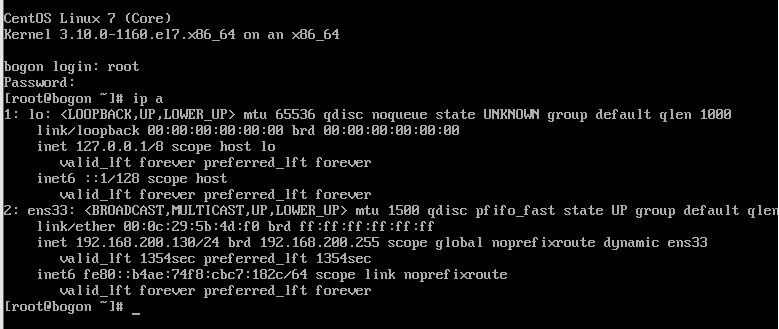
创建虚拟机并查出ip地址进行连接
ip a
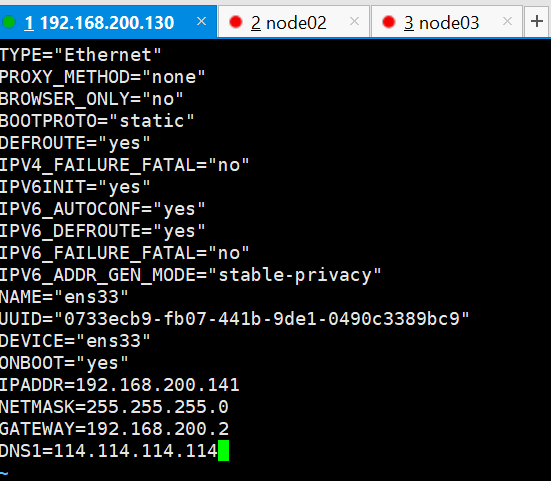
1.配置node01静态ip地址与主机名
vi /etc/sysconfig/network-scripts/ifcfg-ens33
修改或添加如下内容:
BOOTPROTO="static"
ONBOOT=yes
#根据虚拟机网卡信息配置
IPADDR=192.168.200.141
NETMASK=255.255.255.0
GATEWAY=192.168.200.2
DNS1=114.114.114.114
保存退出
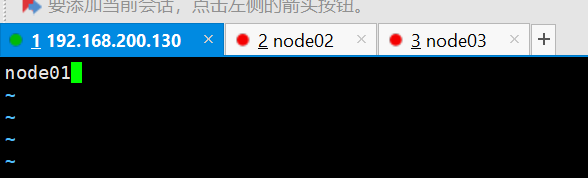
vi /etc/hostname
修改成node01
2.配置域名解析
vi /etc/hosts
192.168.200.141 node01
192.168.200.142 node02
192.168.200.143 node03
3.关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
4.重启虚拟机查看主机名是否修改成功
reboot
通过设置的ip进行远程登录
5.卸载自带的JDK(可能最小化安装,没有默认配置java环境)
1)先查看自带的jdk版本
rpm -qa|grep jdk

- 卸载自带的jdk
yum -y remove java-1.*
3)再使用rpm -qa|grep jdk检查是否卸载完成
6.安装JDK
上传对应的JDK到虚拟机系统
cd切换到压缩包的路径的文件夹
mkdir /usr/java
tar -zxvf jdk-8u161-linux-x64.tar.gz -C /usr/java
配置java的环境变量
vi /etc/profile
在文件末尾添加
export JAVA_HOME=/usr/java/jdk1.8.0_161
export PATH=$PATH:$JAVA_HOME/bin
保存退出
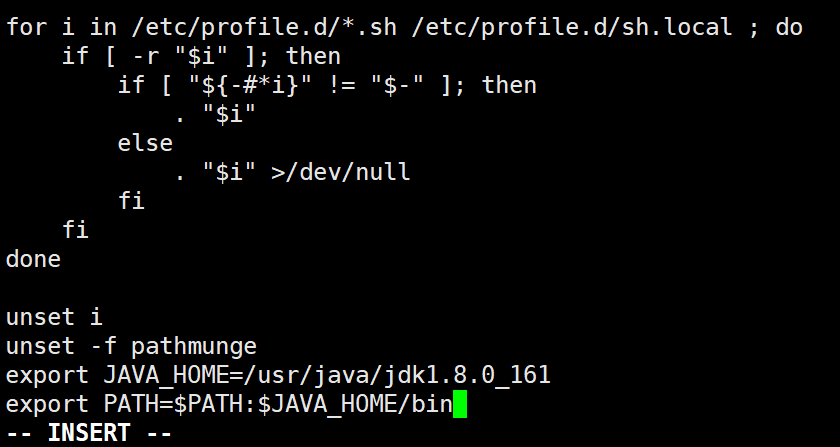
使配置立即生效
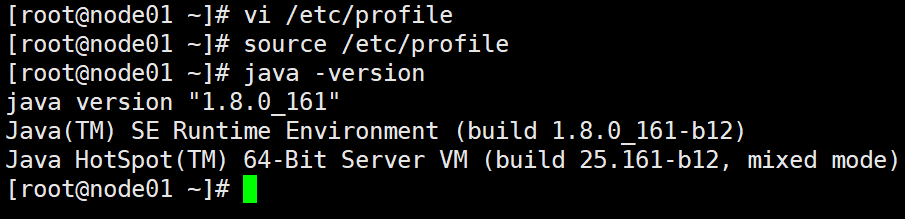
source /etc/profile
检查是否Java配置成功
java -version
7.安装hadoop
上传hadoop,并创建hadoop的安装目录
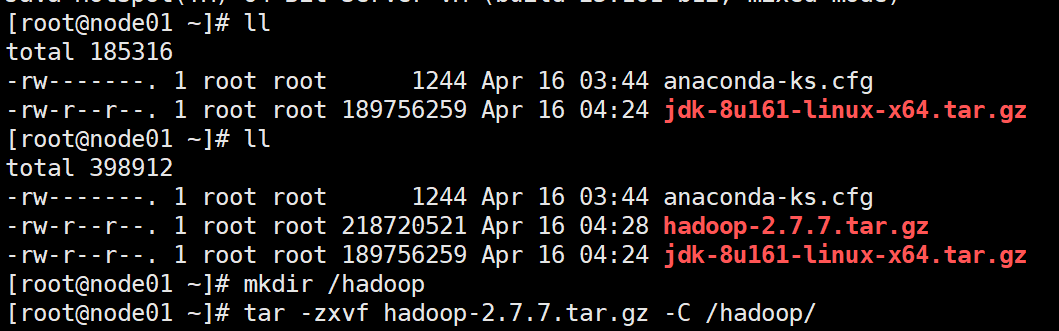
mkdir /hadoop
解压hadoop
tar -zxvf hadoop-2.7.7.tar.gz -C /hadoop/
修改hadoop的环境变量
vi /etc/profile
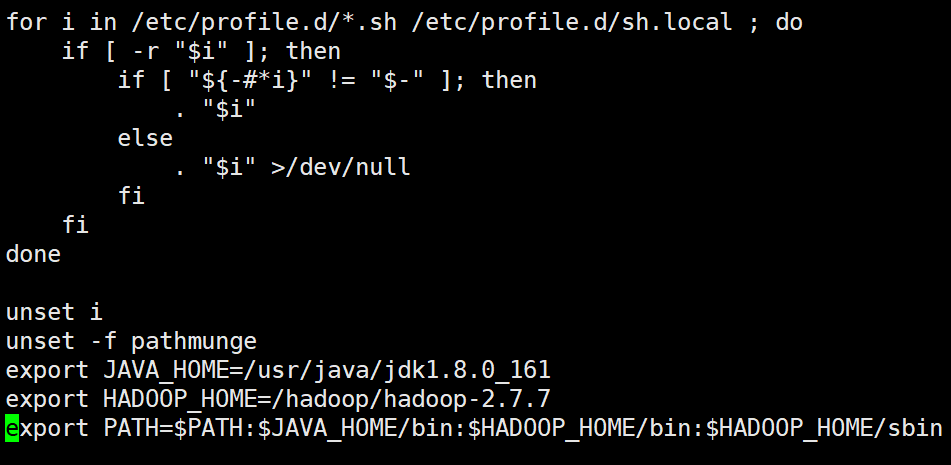
修改内容如下(直接末尾修改):
export JAVA_HOME=/usr/java/jdk1.8.0_161
export HADOOP_HOME=/hadoop/hadoop-2.7.7
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存退出
使用 source /etc/profile 生效配置
8.安装zookerper
上传zookerper安装包
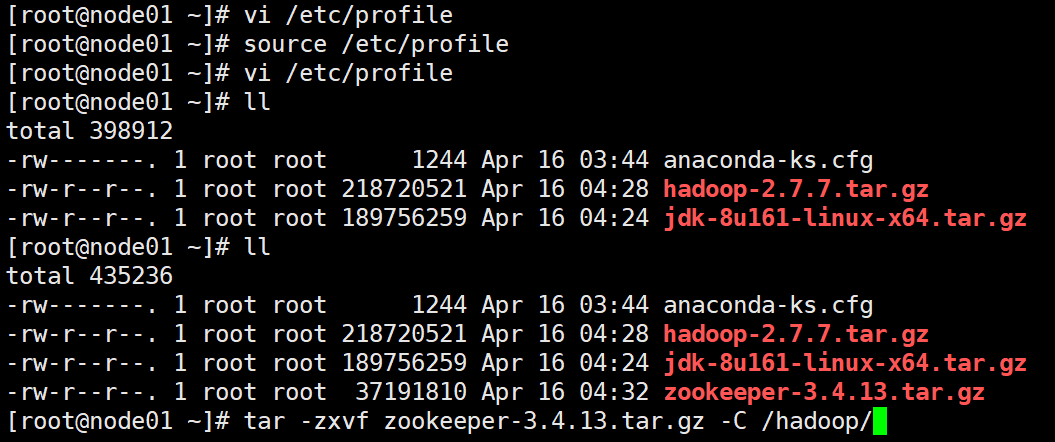
tar -zxvf zookeeper-3.4.13.tar.gz -C /hadoop/
配置zoo.cfg
cd cd /hadoop/zookeeper-3.4.13/conf/
cp zoo_sample.cfg zoo.cfg
修改zoo.cfg文件
vi zoo.cfg
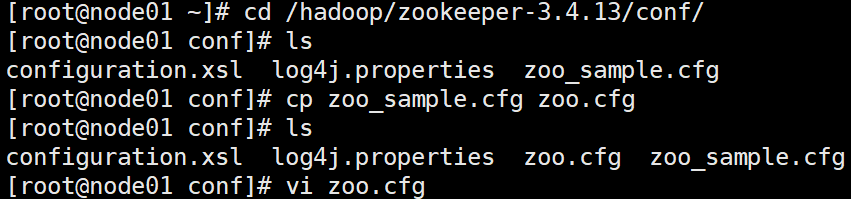
修改以下内容:
dataDir=/hadoop/zookeeper-3.4.13/tmp
server.1=node01:2888:3888
server.2=node02:2888:3888
server.3=node03:2888:3888
保存退出
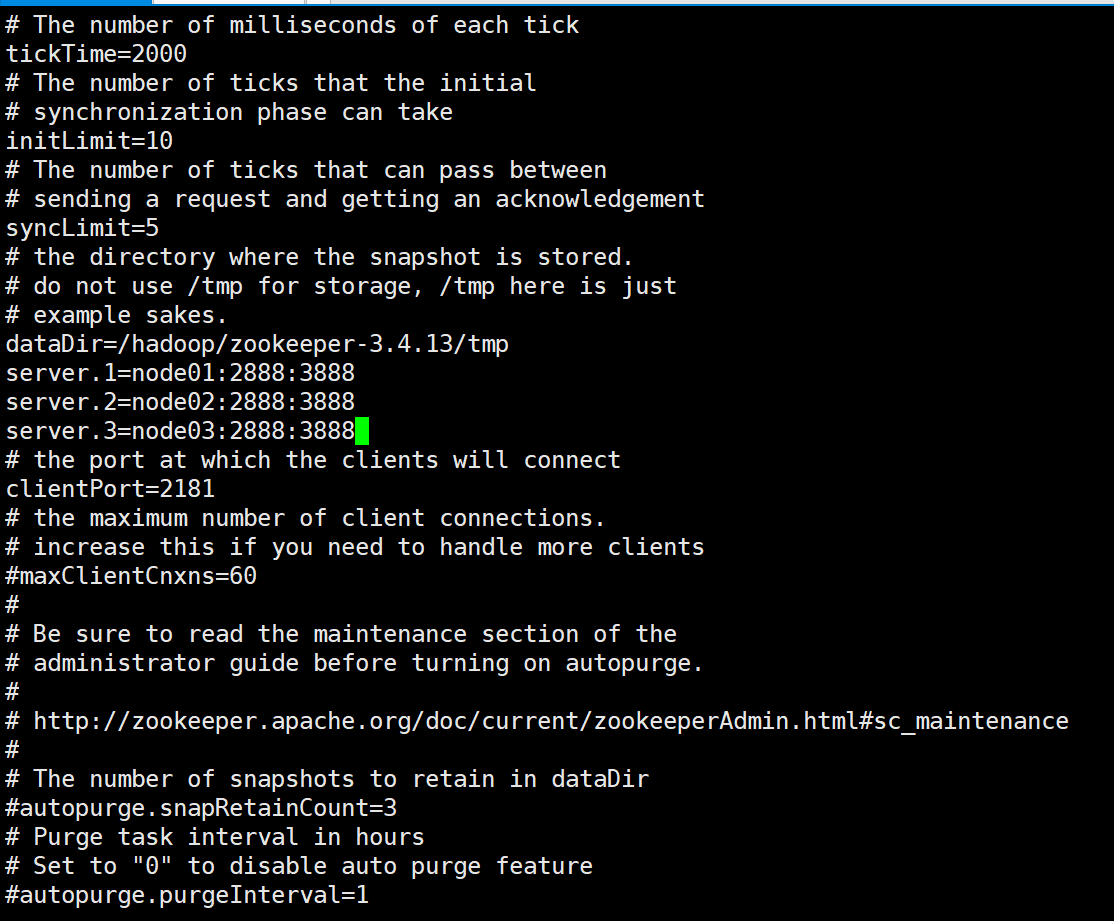
9.修改hadoop配置文件
修改/hadoop/hadoop-2.7.7/etc/hadoop里的配置文件
如果之前的配置和我一样的话,就直接拉进去覆盖
这里就可以打个快照1
10.克隆出其他节点
适当调整内存(我内存小)
修改node02,03的ip地址与主机名
1改2,3
能远程连接上就行
11.配置Zookeeper的id
在zookeeper里创建tmp文件夹,01、02、03都要创建
mkdir /hadoop/zookeeper-3.4.13/tmp
在node01的/hadoop/zookeeper-3.4.13/tmp/myid写入数字1
echo 1 >/hadoop/zookeeper-3.4.13/tmp/myid
02、03节点各自分别执行
echo 2 >/hadoop/zookeeper-3.4.13/tmp/myid
echo 3 >/hadoop/zookeeper-3.4.13/tmp/myid

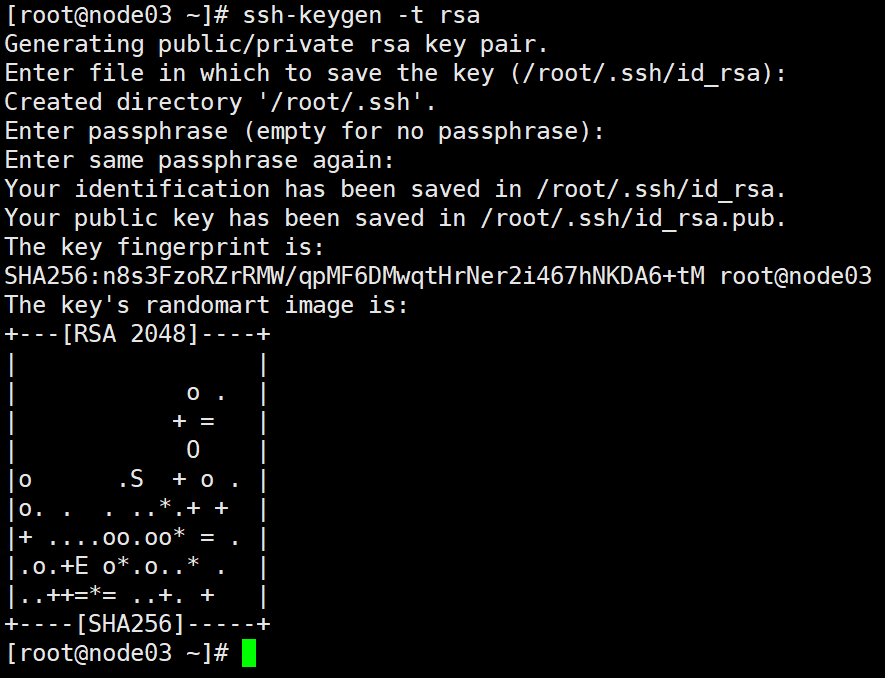
12.配置主机间免密登录(所以节点)
在所以节点执行 (名称、密码不用输入,直接回车到结束)
ssh-keygen -t rsa
复制公钥到其他节点(包括自己)
ssh-copy-id node01
ssh-copy-id node02
ssh-copy-id node03
3个节点重复此操作
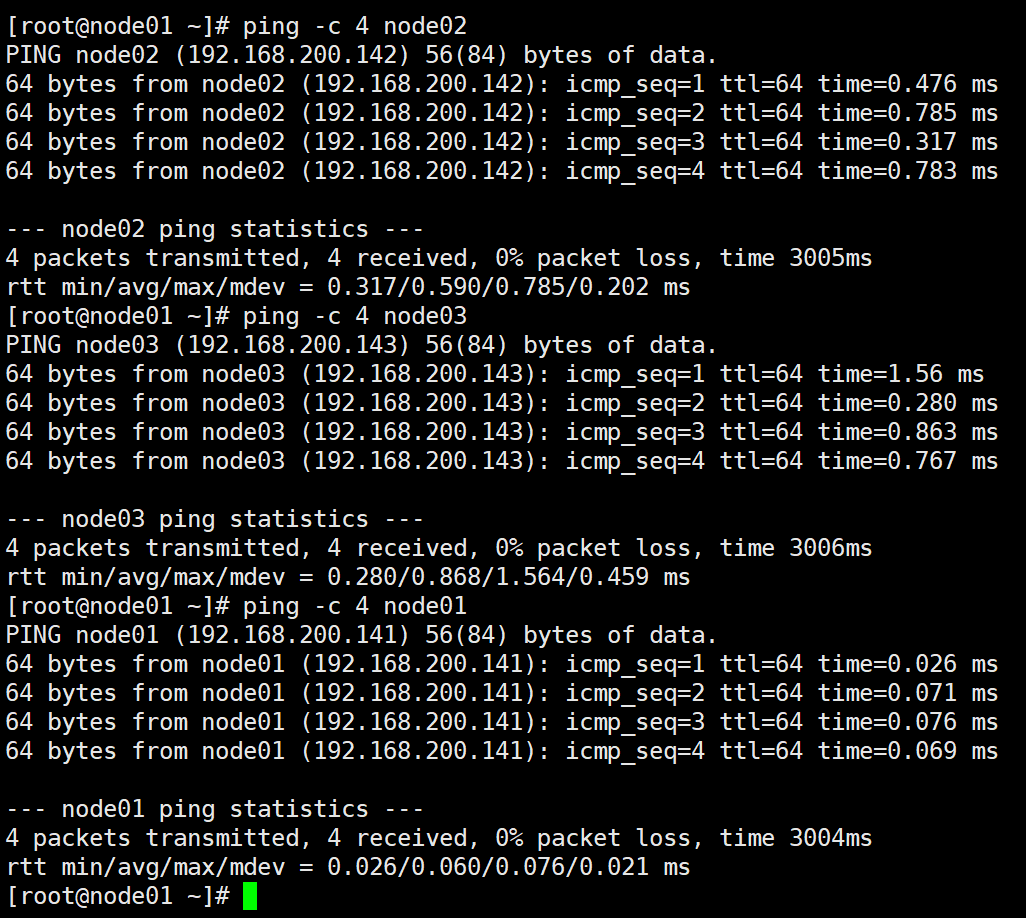
测试连接(3个节点重复此操作)
ping -c 4 node01
ping -c 4 node02
ping -c 4 node03
13.第一次启动Hadoop
1)启动3台节点的zookeeper,在3台节点分别执行
/hadoop/zookeeper-3.4.13/bin/zkServer.sh start
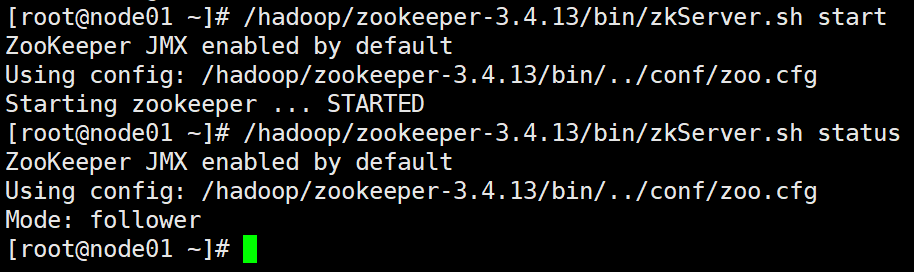
查看状态 /hadoop/zookeeper-3.4.13/bin/zkServer.sh status
停止运行/hadoop/zookeeper-3.4.13/bin/zkServer.sh stop
配置成功,Mode会有1个leader,2个follower(3台的zk启动后再查看状态)
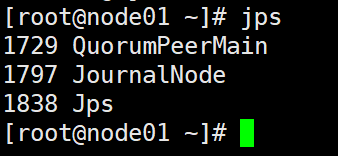
2)启动journalnode,在3台节点分别执行
/hadoop/hadoop-2.7.7/sbin/hadoop-daemon.sh start journalnode

使用jps命令,检查是否有journalnode的进程
3)格式化HDFS,在01节点上执行
hdfs namenode -format
会根据配置的hadoop的tmp文件夹生成文件,3个节点的tmp的数据是一致的
将生成的tmp文件夹复制到02、03上的相同位置
可以使用ftp工具,或者远程复制
scp -r /hadoop/hadoop-2.7.7/tmp/ root@node02:/hadoop/hadoop-2.7.7
scp -r /hadoop/hadoop-2.7.7/tmp/ root@node03:/hadoop/hadoop-2.7.7

4)格式化ZK,在01上执行
hdfs zkfc -formatZK
5)启动hdfs和yarn
cd /hadoop/hadoop-2.7.7
启动hdfs
sbin/start-dfs.sh
启动资源管理器
sbin/start-yarn.sh
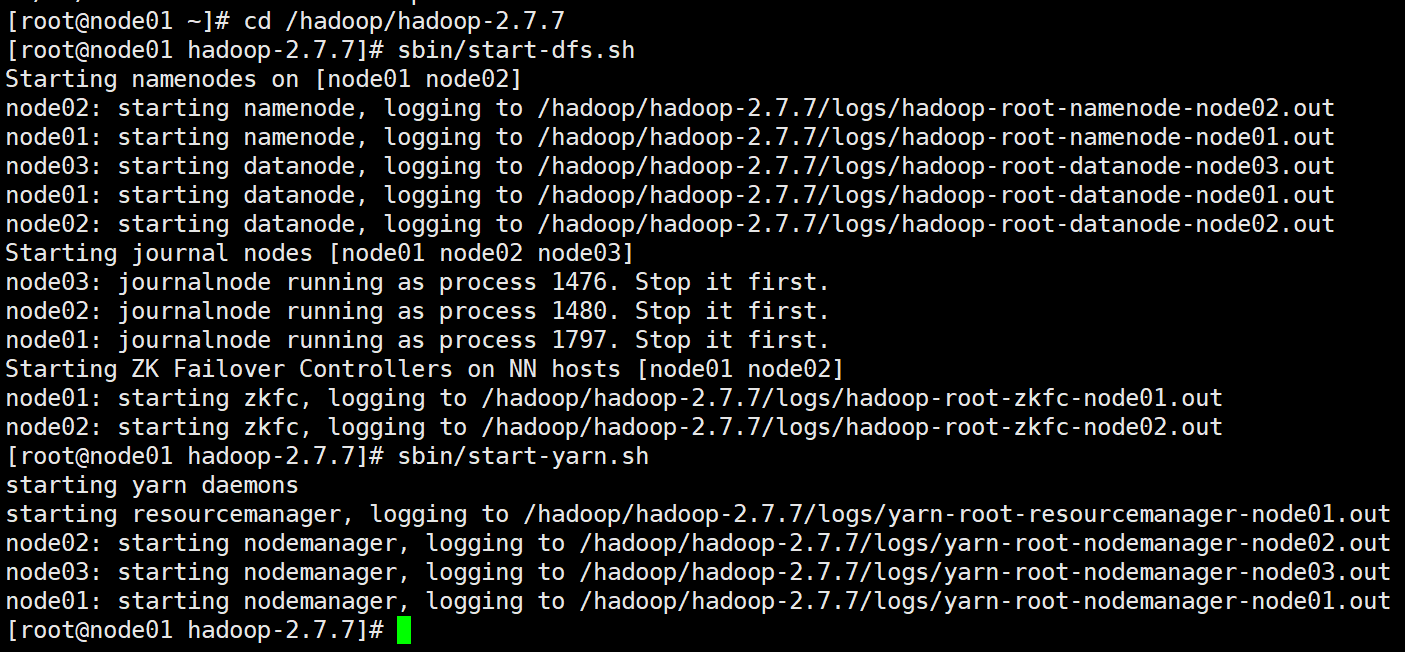
浏览器上访问
192.168.200.141:50070
192.168.200.142:50070
192.168.200.141:8088
6)关闭服务
cd /hadoop/hadoop-2.7.7
关闭hdfs
sbin/stop-dfs.sh
关闭资源管理器
sbin/stop-yarn.sh
停止运行zookeeper,3台节点都执行
/hadoop/zookeeper-3.4.13/bin/zkServer.sh stop
14.成功后再次启动Hdaoop
1)启动3台节点的zookeeper,在3台节点分别执行
/hadoop/zookeeper-3.4.13/bin/zkServer.sh start
2)在node01上,启动hdfs和yarn
/hadoop/hadoop-2.7.7/sbin/start-dfs.sh
/hadoop/hadoop-2.7.7/sbin/start-yarn.sh
15.编写启动脚本
1)修改zookeeper的配置,将java环境直接配置给zk(3个节点都修改)
修改zookeeper的bin/zkEnv.sh文件,添加上java程序的路径,如下:
具体的实现
vi /hadoop/zookeeper-3.4.13/bin/zkEnv.sh
修改内容如下:
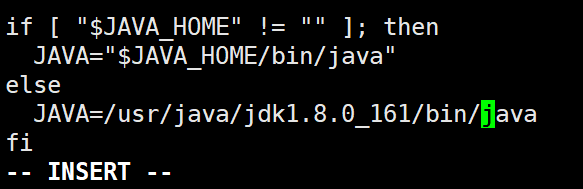
if [ "$JAVA_HOME" != "" ]; then
JAVA="$JAVA_HOME/bin/java"
else
JAVA=/usr/java/jdk1.8.0_161/bin/java
fi
保存退出
在/root下创建文件start-all.sh,启动3台的zk级hadoop服务(仅在node01上创建脚本)
vi start-all.sh
修改内容如下:
#!/bin/bash
echo "====== 启动node01的zookeeper ======"
ssh node01 "/hadoop/zookeeper-3.4.13/bin/zkServer.sh start"
echo "====== 启动node02的zookeeper ======"
ssh node02 "/hadoop/zookeeper-3.4.13/bin/zkServer.sh start"
echo "====== 启动node03的zookeeper ======"
ssh node03 "/hadoop/zookeeper-3.4.13/bin/zkServer.sh start"
echo "====== 启动HDFS ======"
/hadoop/hadoop-2.7.7/sbin/start-dfs.sh
echo "====== 启动资源管理器YARN ======"
/hadoop/hadoop-2.7.7/sbin/start-yarn.sh
在/root下创建文件transNodeState.sh,设置01为主节点,02为备选主节点
vi transNodeState.sh
修改内容如下:
#!/bin/bash
hdfs haadmin -transitionToStandby --forcemanual nn2
hdfs haadmin -transitionToActive --forcemanual nn1
实现停止集群服务的脚本(先启动的后关,后启动的先关)
vi stop-all.sh
修改内容如下:
#!/bin/bash
echo "====== 关闭资源管理器YARN ======"
/hadoop/hadoop-2.7.7/sbin/stop-yarn.sh
echo "====== 关闭HDFS ======"
/hadoop/hadoop-2.7.7/sbin/stop-dfs.sh
echo "====== 关闭node03的zookeeper ======"
ssh node03 "/hadoop/zookeeper-3.4.13/bin/zkServer.sh stop"
echo "====== 关闭node02的zookeeper ======"
ssh node02 "/hadoop/zookeeper-3.4.13/bin/zkServer.sh stop"
echo "====== 关闭node01的zookeeper ======"
ssh node01 "/hadoop/zookeeper-3.4.13/bin/zkServer.sh stop"

16.测试脚本是否可用
1)检查启动脚本是否可用(可以多启几次)
sh start-all.sh
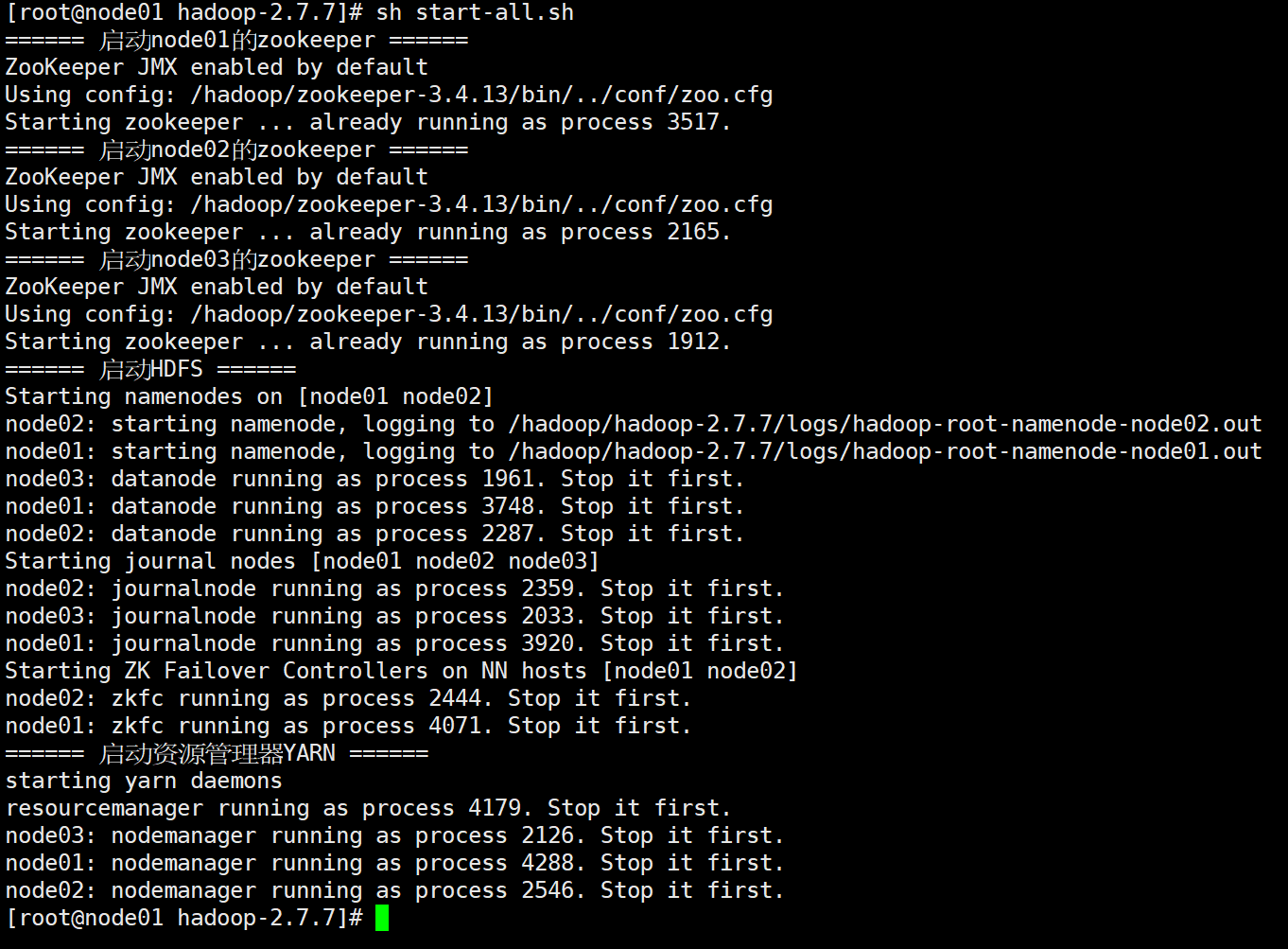
浏览器访问
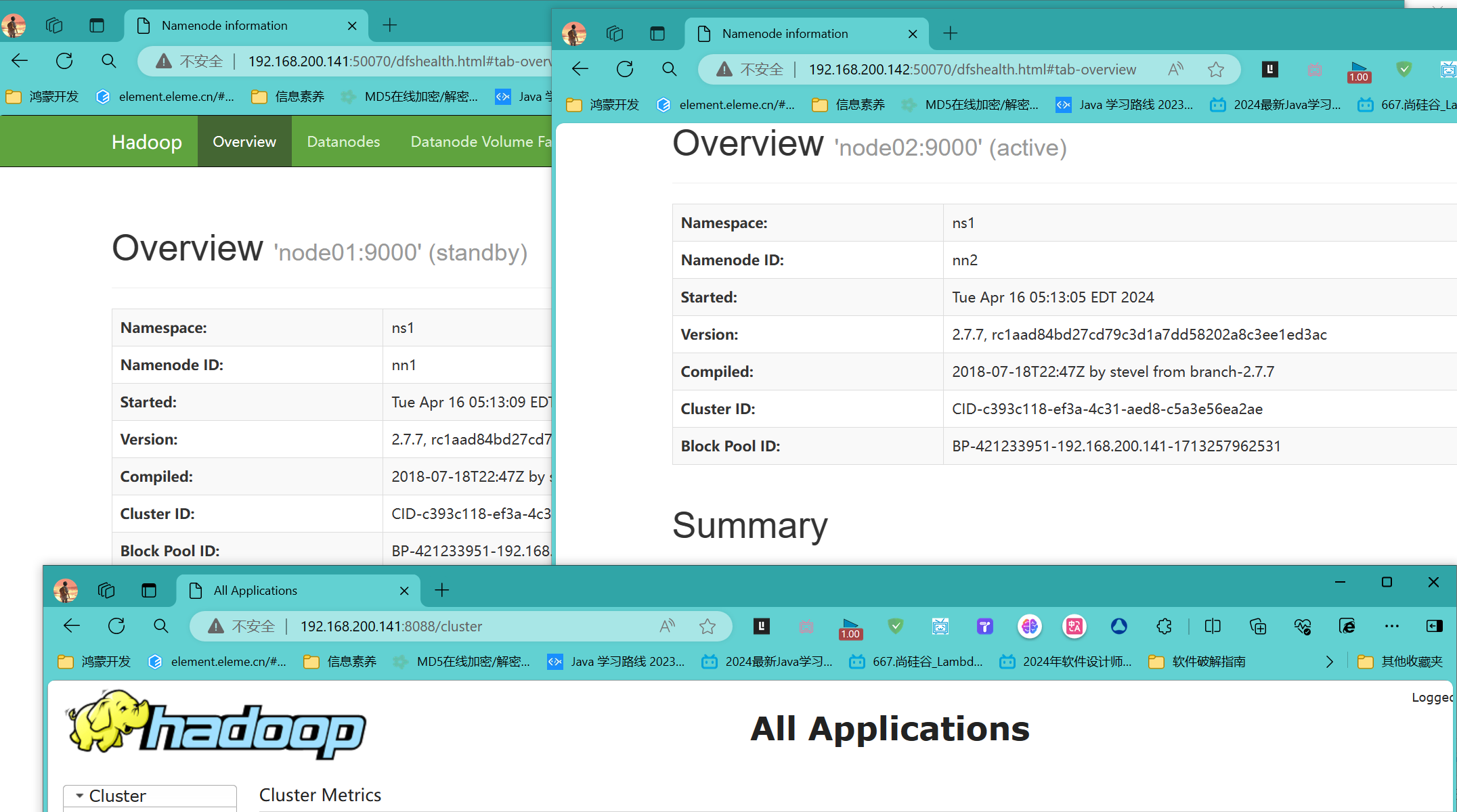
2)可以看到node01为备用节点,手动调整node01为主节点
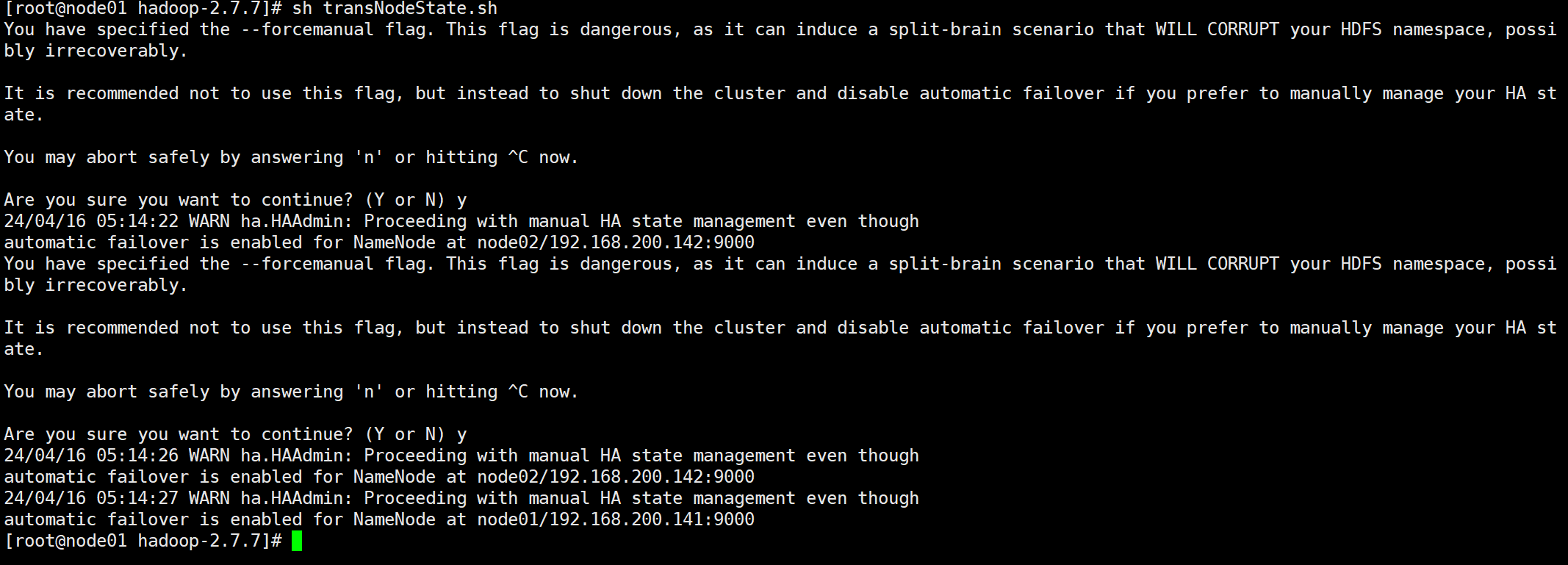
sh transNodeState.sh
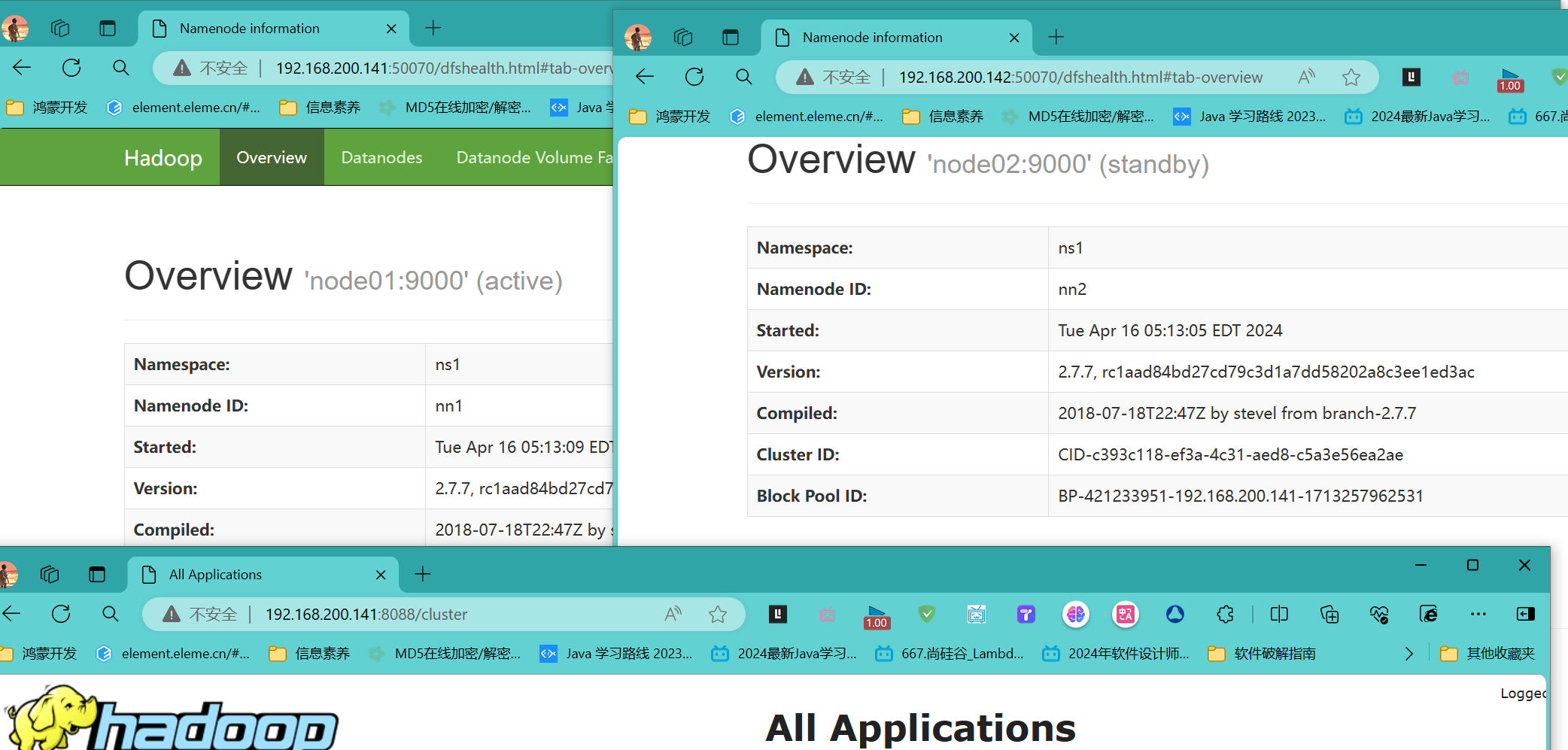
再次浏览器查看
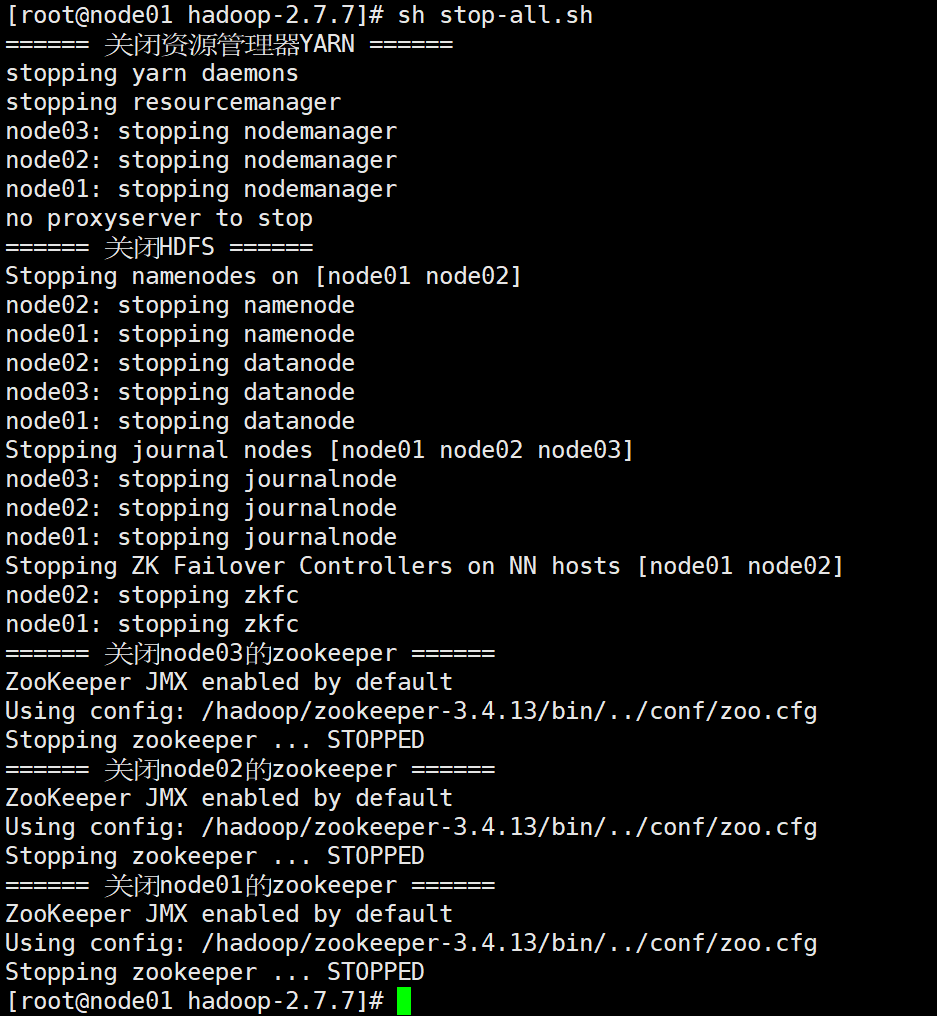
3)关闭所有服务
sh stop-all.sh
把所有的脚本都移动到/root下
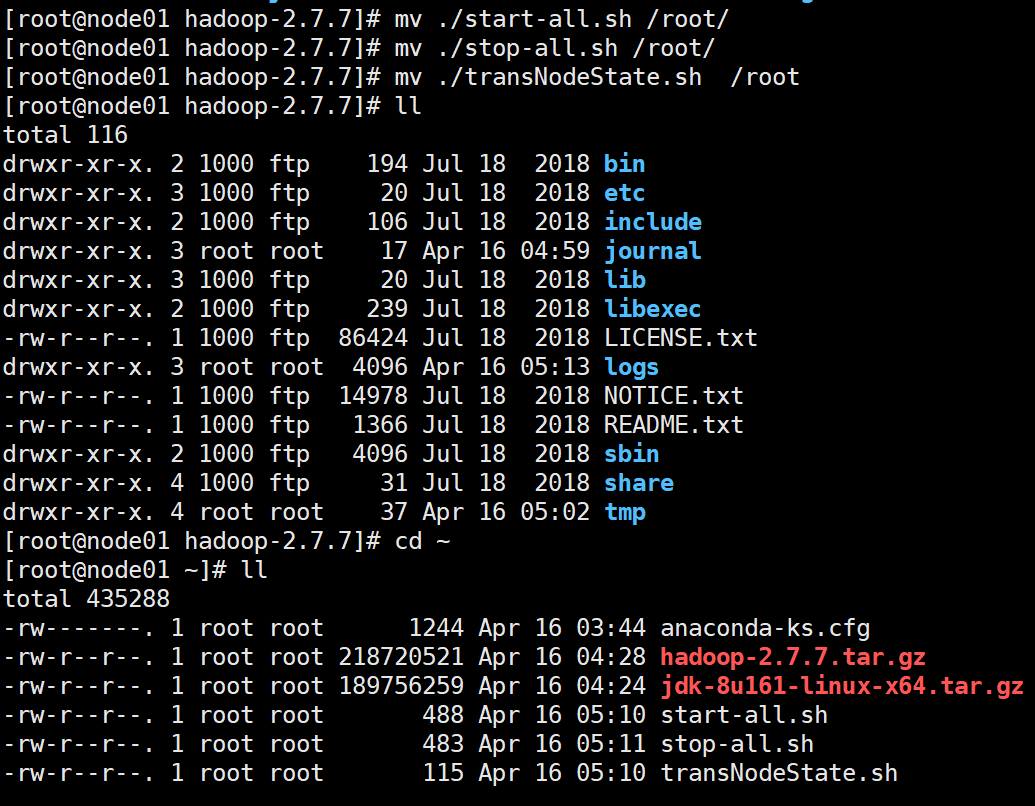
17.打快照2
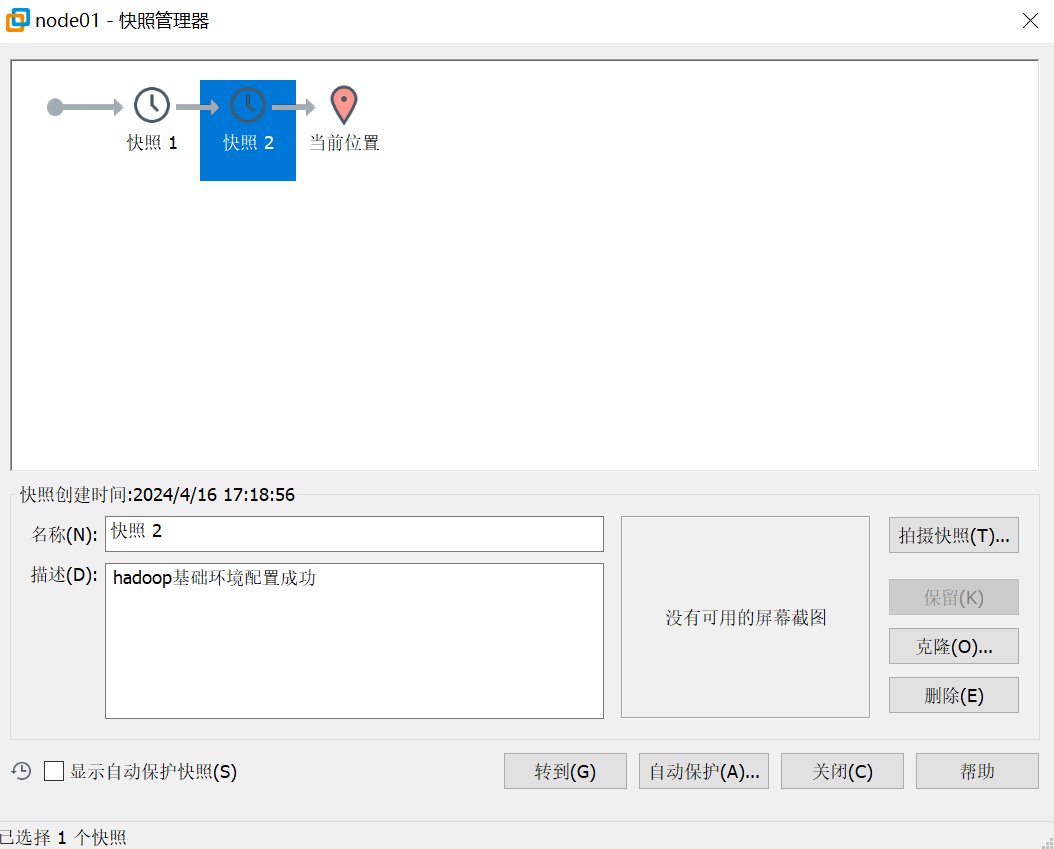
内容:hadoop基础环境配置成功(3个节点都打快照)
据说关机,再打快照,更省空间

感谢大家的支持,关注,评论,点赞!
再见!!!
原文地址:https://blog.csdn.net/weixin_51202460/article/details/137834921
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!