elasticSearch
概念
分析数据
加入倒排索引之前,es在其主体上进行的操作:
字符过滤 转变为字符 / 文本切分单|多个分词 / 分词过滤转变分词 / 分词索引存储到索引
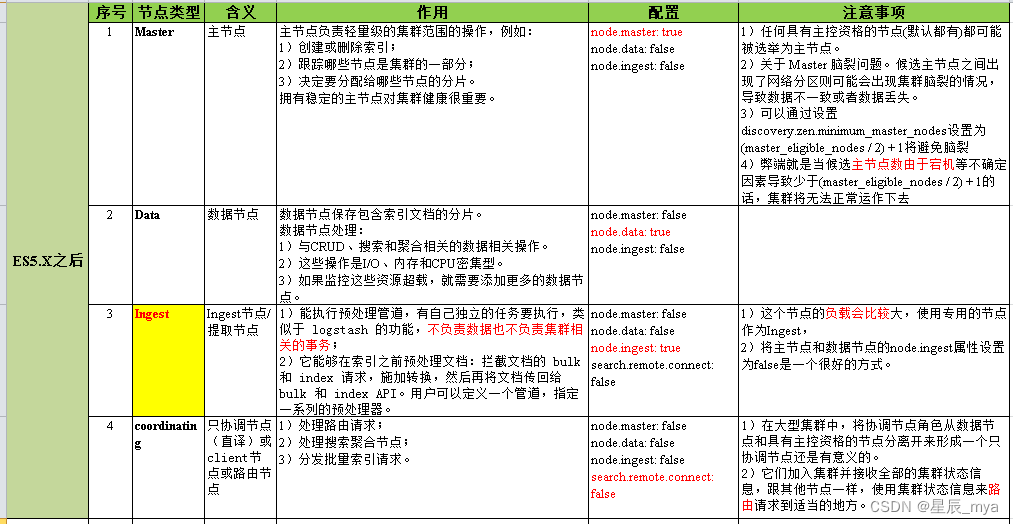
节点:node es实例
cluster.name 相同 集群,承担数据 负载压力
- 主节点:集群范围内all变更
- 数据节点:存储数据和对应倒排索引,默认都是,node.data设置
- 协调节点:node.master和node.data=false则为协调节点,响应请求,均衡负载
分片:水平分表 一个分片lucene实例
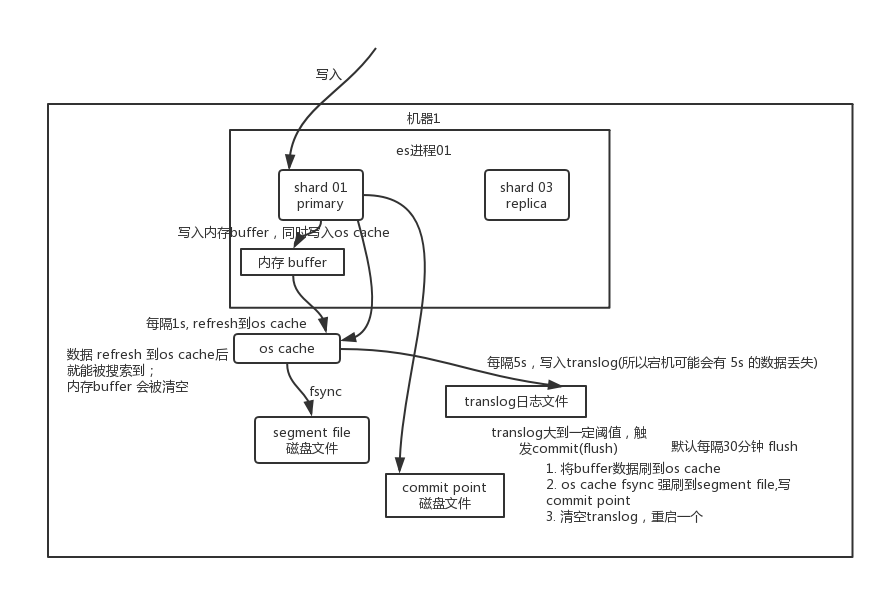
写入:
分段存:索引文件被分成段,不变性 本身是倒排索引,写入不可改
文件系统缓存
段写入到磁盘生成提交点,记录all提交后段信息的文件,只读
段在内存,只写的权限,不能被检索
新增:新增段就ok
删除:新增.del文件,列出被删段信息,可被查到 最终结果被返回前从结果集中移除
更新:删除+新增,旧的文件标记del文件,新版索引到新段
冲刷:refresh
新数据先写入内存
文件系统缓存:1s 内存达到一定量 触发刷新refresh 新段 存储到 文件缓存系统
磁盘:提交点 刷盘
冲刷 flush
内存分段提交到磁盘
translog 事务日志,记录每次es的操作
flush 事务被清空,段全量提交到磁盘
内存缓存满了/flush超过一定时间/事务日志达到阈值
段合并merge
提升搜索性能 均衡I/O CPU计算能力
分段总量保持可控范围内,每个搜索请求轮流检查每个段 段多检索慢
真正的删除文档
数据查询
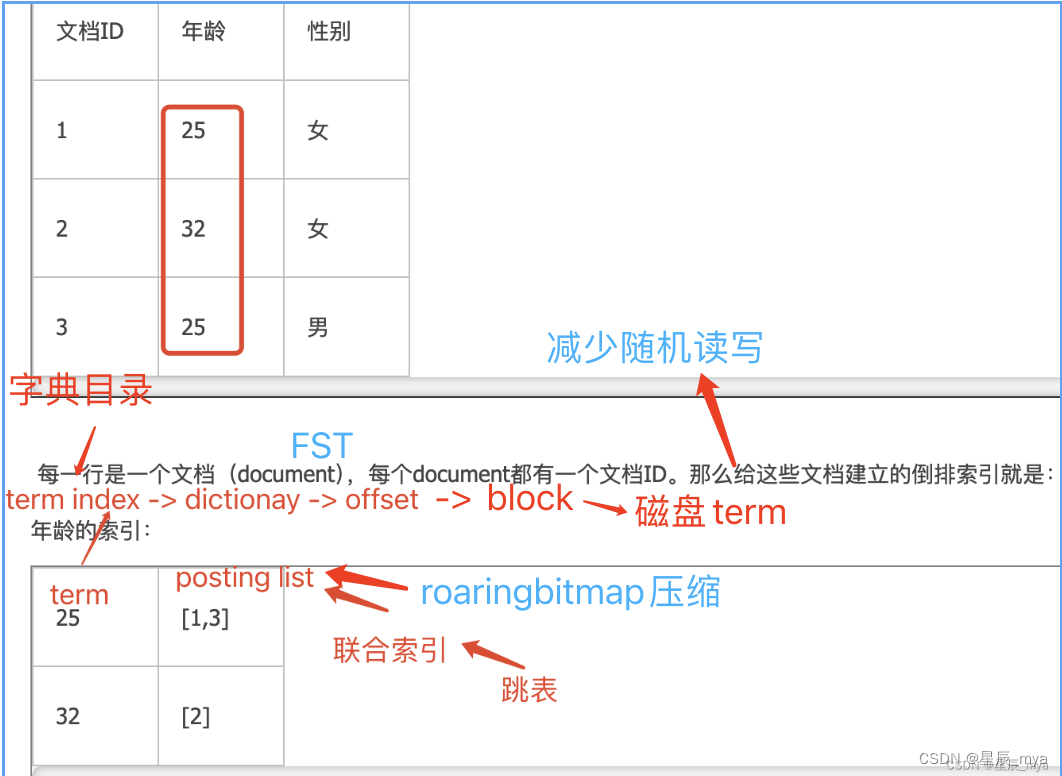
文档经过analyzer处理(分词/去停用词/单复数/时态) term 文档编号 词频
索引优化: 给term排序 二分查找 logN
term index:A开头的有哪些term 分别在哪页
含term的前缀,通过term index快速定位到term dictionary的某个offset 磁盘顺序查找
from size: 普通的分页查询
scroll:快照,每次只能获取一页的内容,然后会返回一个scroll_id
search_after:依赖上一次查询的结果 高效 可扩展 大规模分野 实时
整理:Elasticsearch 三种分页方式_es search after原理-CSDN博客
filter执行原理
query之前执行,过滤掉多的数据
倒排索引中查找搜索串, 文档id bitset 过滤 追踪query,近256个query中超过次数 缓存bitset,小的segemtn不需要缓存,提升性能
bitset由es自动更新
倒排索引
每个字段都有自己的倒排索引
联合索引:
skip list
跳表 同时遍历多个term的posting list 互相skip
跳表:多层有序链表组成 最低层level1含all元素,含指针
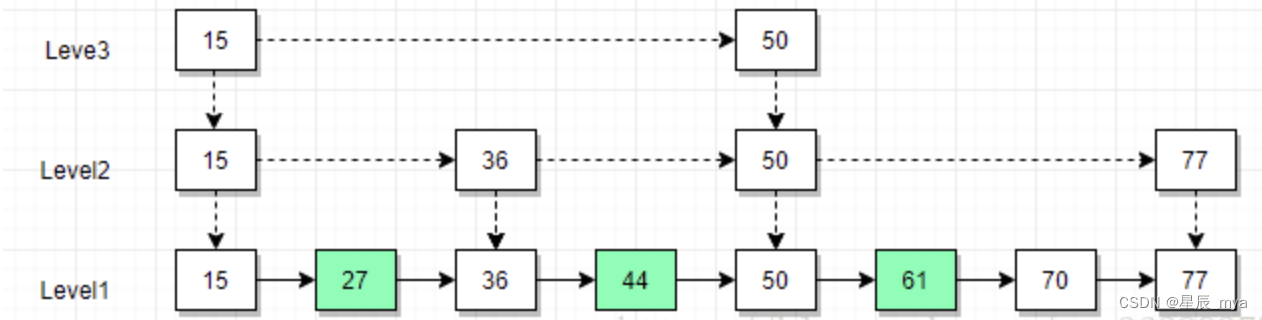
多数据量使用跳表 效果显著
少的使用bitset 压缩 按位与 得到最后的交集
使用bitset数据结构,多个term求出bitset,对bitset做AN操作
FST压缩
内存 存 more数据,内存FST压缩term index (内存里)
- 空间占用小,对词典中单词前缀和后缀重复利用 压缩了存储空间
- 查询块,O(len(str))
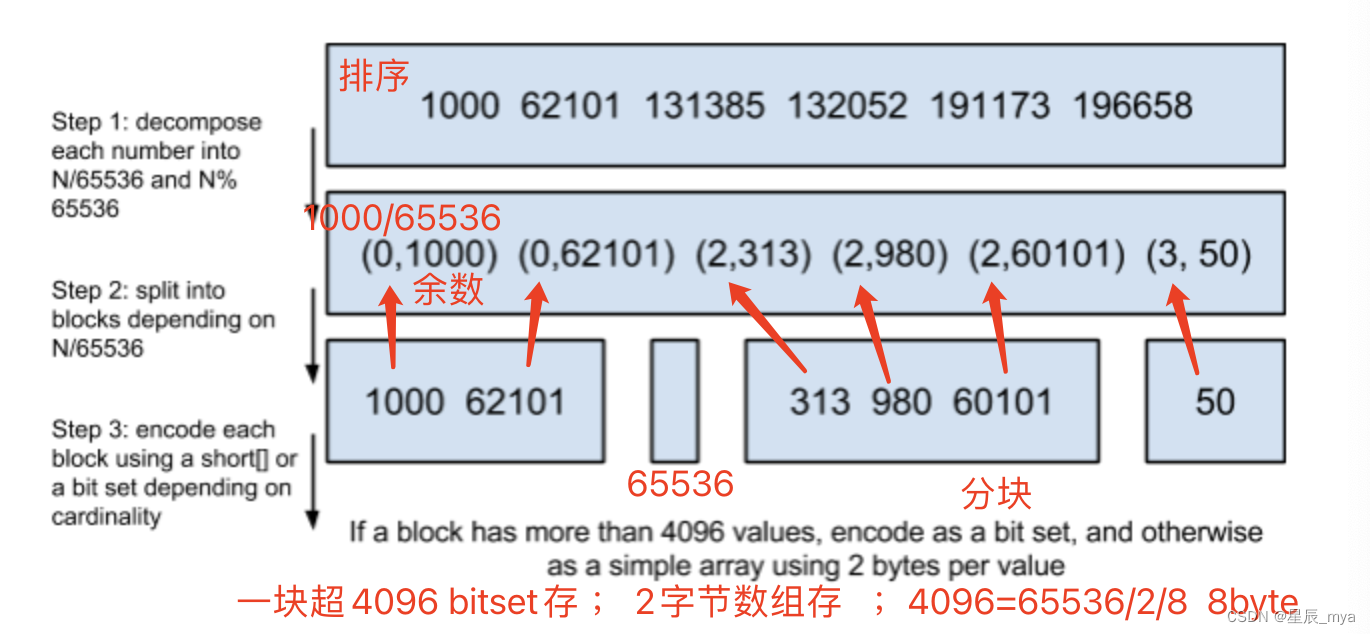
Roaring Bitmap
posting list存储文档id,id很大的时候压缩,排序和大数变小数
打分机制
得分:搜索词条的频率以及它有多常见(一个文档中)
TF-IDF,多个文档中越多越不相关,and you,and 出现的次数多不重要
master选举
ZenDiscovery模块复制,ping rpc发现彼此 unicast
多个node当选master,脑裂 破坏数据一致性,导致集群不可控
分布式 投票,master被多节点认可,保证只有一个
discovery.zen.minimum_master_nodes=sum(node)/2+1 多半
- 可称为master的节点 据nodeId字典排序,每次选举节点将all节点排序 选第一个认为master
- 先根据clusterStateVersion比较,大 优先级高 相同 进入compareNodes,内部按节点的id比较
脑裂:
- 网络问题,节点访问不到master 开始选举
- 节点负载高 es响应延迟 任务挂了 重新选
- 内存回收,占用内存太大 大规模回收
- ping_timeout响应时间超3s,可改
- 选举触发 discovery.zen.minimum_master_nodes:1最小集群主节点数量,
master候选等待多数节点join后才能成为master,保证master得到认可
raft算法,选举周期term 每周期只能投一票 再投就是下一周期,如最后两个节点都认为自己是master,两个term都收集到了多数派的选票,多数节点的term是较大的那个
集群
去中心化
shards
索引分片,es可把完整索引分成多个分片,可以把一个大的索引拆分多个分布到
replicas:索引副本,可设置多个索引副本
masterNode该节点不和应用创建连接,保存集群状态
修改节点状态信息以及处理元数据:索引增 删 分片路由 索引相关的mapping/setting
recovery:数据恢复/数据重新分布,节点加入/退出 据机器负载对索引分片重新分配
ingest:大数据处理环节的ETL 抽取 转换 加载
数据前置处理转换的节点,pipeline管道 过滤转换
数据转换和丰富,20个内置处理器 grok date gsub
批量请求或索引操作前,ingest拦截请求 处理文档
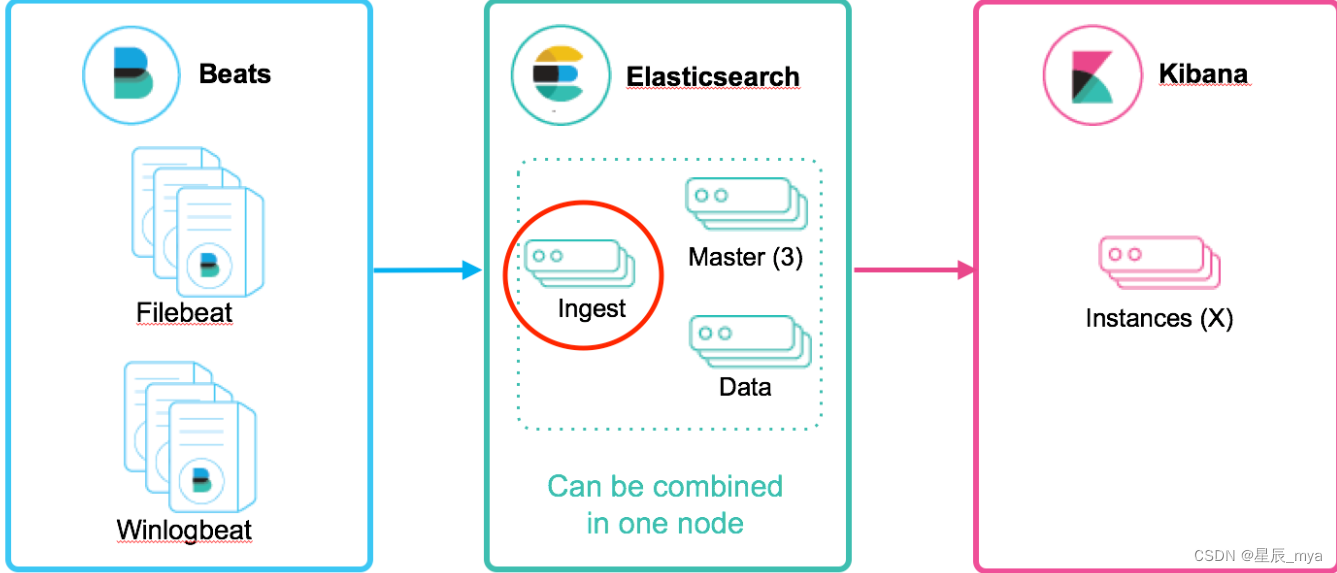
logstash:大量输入/出插件,支持不同架构;在本地缓存数据,集成大量不同消息队列
ingest:批量bulk 索引index请求将数据推送es,长时间无法联系es丢数据;28种类处理器操作 单一事件上下文运行
高可用
- 自动处理节点的加入和离开
- 自动同步改变的集群状态
- 当集群发生故障时自动切换主副shard
每个索引分成多个分片shards进行存储,分片会分布式部署在多个不同的节点
副本分片:容错/ 请求的负载均衡
状态同步:
- 主节点改变集群状态,publish给其他节点
- 其他节点回复确认,不改变本地集群状态
- 在discovery.zen.commit_timeout30s时间内未收到discovery.zen.minimum_master_nodes个节点确认信息,改变的状态=rejected
- 收到了,提交commit该状态的改变,其他节点发送该改变
- 其他节点收到,应用到本地的集群状态,主节点发送成功信息
节点加入离开
discovery.zen.ping.unicast.hosts配置的节点获取集群状态,找到master节点,发送一个join request(discovery.zen.join_timeout),主节点接收到request后,同步集群状态到新节点
非主节点出现3次ping不通的情况(ping_interval 默认为1s;ping_timeout =30s),主节点会认为该节点已宕机,将该节点踢出集群
当主节点发生故障,集群中的其他节点将会ping当前的master eligible节点,并从中选出一个新的主节点
通过配置discovery.zen.minimum_master_nodes防止集群出现split brain:检查集群中master eligible的个数来判断是否选举出一个主节点。其个数最好设置为(number_master eligible/2)+1,防止当主节点出问题时,脑裂问题
节点可以通过设置node.master为false来阻止自己变为一个主节点
从active master eligible node被选举为master节点, 没有 从masterCandidates选出id最小的节点
分片副本同步
每个 shard 都有自己的Allocation ID区分
集群级元信息中记录了最新shard 的Allocation ID集合 in-sync allocation IDs
主副shard没有同步,那么副本的shard会将被从in-sync allocation IDs踢出
shard为 节点的平方数
一个shard 30-50G,SSD固态硬盘100G
*T数据 一个分片50G 主分片20个 400个
架构:
海外社交,用户比较多
shard数不能太多 master单独做client节点
elasticsearch高可用 原理 (图解+秒懂+史上最全)-CSDN博客
Elasticsearch Curator 数据迁移
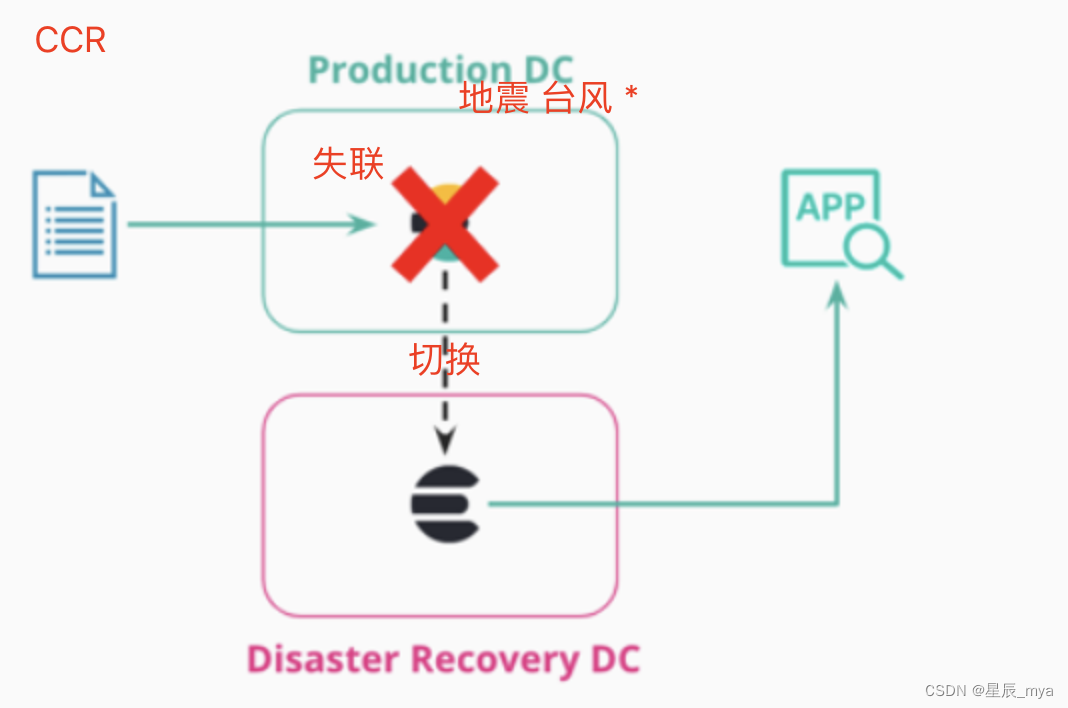
CCR cross-cluster replication
索引复制其他es集群,数据中心高可用HA 灾难回复DR CDN样体系
一个集群被多个集群订阅,复制到多个集群
follower拉取pull leader的数据,follower不能写入
平衡算法 扩容 减容 导入数据
Elasticsearch 主从同步之跨集群复制-CSDN博客
这个网速 写了很多没保存
其他
调优
- 较小索引分片提高查询性能/增加副本冗余负载均衡
- 硬件,优化JVM
- 别名进行索引管理
- 每天定时对索引force_merge操作,释放空间
- 冷热分离,热数据SSD 提交效率,冷数据定期shrink 缩减存储
- 合理设置分词器,合适索引结构 合理字段映射 分析器 索引设置
- mapping的时候结合字段属性,是否需要检索/存储
- 写入前关闭刷新副本=0,bulk写,自动生成id,写后恢复副本数 刷新间隔
- 禁止%like%,禁批量terms,合理路由机制,量大先基于时间敲定索引在检索
- 使用filter过滤器代替普通查询,结果限制必要字段
部署时关闭缓存swap/
使用:
20个节点,香港 印度 中东 欧洲 美国 巴西
20+索引 不同业务 35G左右 索引大小200G
20个分片 40个副本
https://www.cnblogs.com/liang1101/p/7284205.html
https://blog.csdn.net/laoyang360/article/details/78290484
https://www.jianshu.com/p/716408af7ebb
https://blog.csdn.net/laoyang360/article/details/93376355
https://segmentfault.com/a/1190000021614149
https://www.jianshu.com/p/716408af7ebb
https://discuss.elastic.co/t/dec-22nd-2018-cn-elasticsearch-ccr/161626
https://www.elastic.co/guide/en/elasticsearch/reference/7.5/indices-split-index.html
https://www.elastic.co/guide/en/elasticsearch/reference/6.1/indices-split-index.html
ES7基础篇-10-SpringBoot集成ES操作-CSDN博客
https://www.cnblogs.com/acestart/p/14884380.html
https://www.cnblogs.com/lxcmyf/p/14276974.html
elasticsearch高可用 原理 (图解+秒懂+史上最全)-CSDN博客
https://so.csdn.net/so/search?q=elasticsearch&t=blog&u=ma15732625261&urw= 之前17年18年写的水文 别看这么多 其实挺简单
原文地址:https://blog.csdn.net/ma15732625261/article/details/137723725
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!