Hive的“分区”
partition by
根据表中的字段名进行分区,常用在建表语句、窗口函数。
-- 建表
create table test(log string) partitioned by(etl_date string);
-- 窗口函数
select row_number() over(partition by user_id order by exec_time desc) as rn from dual;
distribute by
根据表中的字段值进行分区,
首先确定要分区的数量,然后拿字段值%分区个数,余数相同的进入同一分区。
set mapred.reduce.tasks=2;
insert overwrite local directory '/home/hadoop/distri_data' select * from user_install_status_limit distribute by country sort;
-- 相同hashcode的国家名分到同一个reducer文件中.
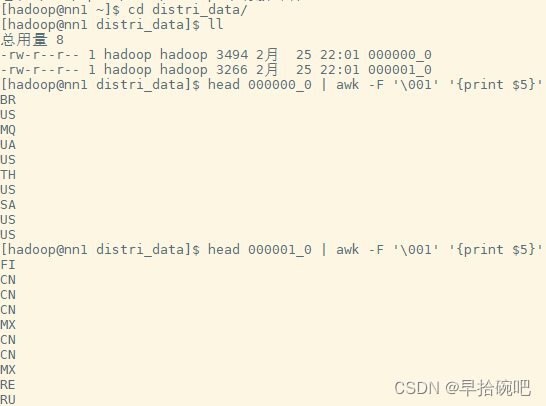
cluster by
cluster by column = distribute by column + sort by column
(必须是相同的column才能相等,否则distribute by和sort by 要各自指定列),
即:又分桶又进行内部排序.cluster by可以保证组内有序.
注意,都是针对column列,且采用默认ASC(升序),不能指定排序规则为asc或者desc.
set mapred.reduce.tasks=2;
insert overwrite local directory '/home/hadoop/cluster_data' select * from user_install_status_limit cluster by country;
--等于
insert overwrite local directory '/home/hadoop/cluster_data' select * from user_install_status_limit distribute by country sort by country;
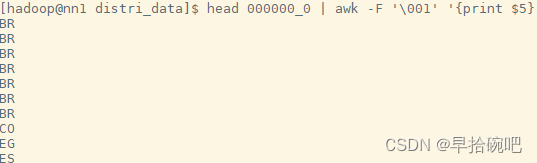
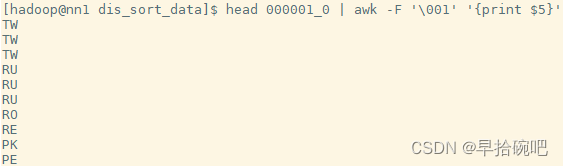
实现降序
需要用distribute by and sort by 组合的方式,
在创建桶表的语法中clustered by桶内是否有序要根据sort by决定.
set mapred.reduce.tasks=2;
insert overwrite local directory '/home/hadoop/dis_sort_data' select * from user_install_status_limit distribute by country sort by country desc;
原文地址:https://blog.csdn.net/weixin_44872470/article/details/138905805
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!