Hadoop3:客户端向HDFS写数据流的流程讲解(较枯燥)
一、场景描述
我们登陆HDFS的web端,上传一个大文件。
二、流程图
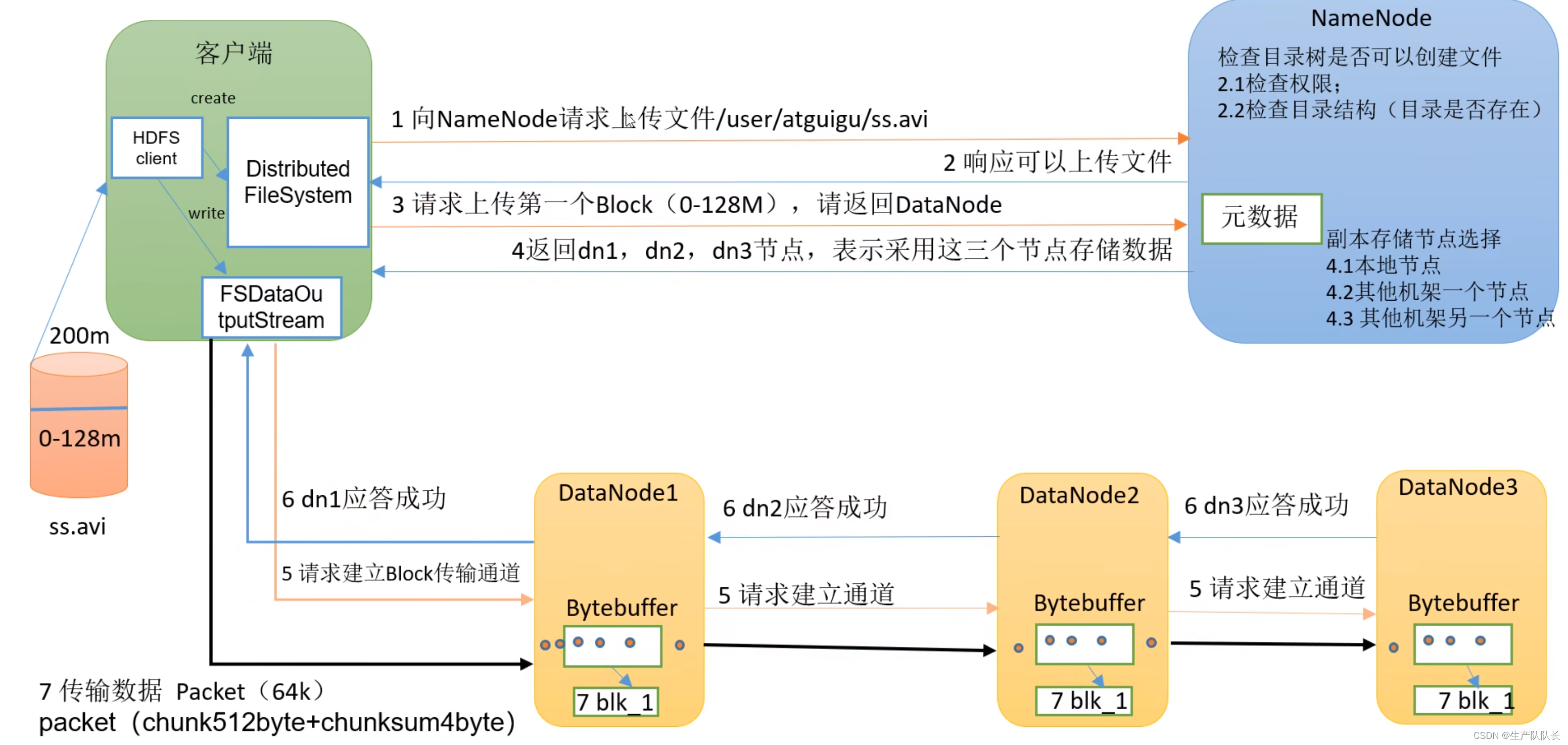
三、讲解
流程1(Client与NameNode交互)
1、HDFS client创建DistributedFileSystem,通过dfs与NameNode进行2次(一来一回4次)对话(request和response),如图所示。
2、第1次请求,NameNode会进行2.1和2.2的检查工作。
3、第2次请求,上传一个Block,NameNode选定的存储数据的节点(DataNode),返回给client。
流程2(Client与DataNode交互)
4、HDFS client创建FSDataOutputStream(一种输出流),通过它和集群中选定的存储数据的DataNode交互
5、首先,和选定的DataNode打通数据流通道。
这里,client只需要和最近的节点直接交互,其他副本节点和该节点交互,无需和client交互。这里涉及到最近节点距离计算。
6、开始传输数据给最近节点,这里传输的时候,DataNode会先存一份在内存,同时,用内存的数据,写入磁盘和传输到其他DataNode节点。就是图中第7步。
7、所有节点存储完成后,依次返回ack(了解消息队列的,比如kafka,都知道ack是什么吧),告知存储结果。最终由最近节点,反馈给client存储结果。
8、当一个Block传完之后,客户端会再次请求NameNode,再次上传一个Block。重复步骤3-8,直到,完整的文件传输完毕。
原文地址:https://blog.csdn.net/Brave_heart4pzj/article/details/138911971
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!